Reasoning AI - Pre-train LLM 使用手册
Reasoning AI - Pre-train LLM 使用手册
此文不对 NLP 算法做过多解释,也不对各个工具的原理进行解释,主要是使用方式
Pre-train LLM 概览
预训练的大语言模型(Pre-trained Large Language Model)是一种基于深度学习的 NLP 模型,它经过大规模文本数据的预训练,能够理解和生成自然语言文本
这些模型通常基于 Transformer 架构,通过处理海量的无监督文本数据,学习语义、句法和上下文关系
LLM 有以下三种工作原理:
- 自回归模型:持续预测下一个单词。例如 OpenAI 的 GPT 系列
- 自编码模型:掩盖部分文本,预测被掩盖的单词。例如 BERT
- 混合模型:结合两种方法,例如 Google 的 T5(Text-To-Text Transfer Transformer)
值得一提的是,现在常见且主流的 LLM 基本都是自回归模型
Decoder-Only 架构
Decoder-Only 架构是 Transformer 模型的一种变体,主要用于自回归任务,如文本生成
与标准的 Transformer 不同,Decoder-Only 架构仅使用 Transformer Decoder 部分,专注于根据输入序列生成目标序列
目前主流的 LLM 大多采用 Decoder-Only 架构,如 OpenAI 的 GPT 系列、Anthropic 的 Claude、Meta 的 LLaMA 系列,以及 Google 的 Bard(部分版本)
一个经典的 Decoder-Only 架构由 文本嵌入层、多层解码块、线性输出层 组成
以 GPT-2-Small 模型的架构为例:
1 | GPT2Model( # 完整的 GPT-2 模型 |
这里不对 NLP 算法做过多解释,上述架构来源于 OpenAI 公布的 GPT-2 报告
Decoder-Block 实际上就是 Transformer Decoder Layer,或者其改进版
上文中每个 GPT2Block 单独展开为:
1 | GPT2Block( # 单个 GPT-2 Transformer 解码器块 |
上述架构来源于 OpenAI 公布的 GPT-2 报告
这里不对 NLP 算法做过多解释,有 NLP 基础的人都能看出来 GPT2Block 与 Transformer Decoder Layer 非常相似
Decoder-Only 的超参数
对于 Decoder-Only 架构而言,其超参数的设置类型几乎是固定的
| 超参数 | 作用 | GPT-2-Small 的设置 |
|---|---|---|
| 隐藏维度 (hidden size) | 每个 token 的向量维度 | 768 |
| 层数 (num layers) | Transformer 解码器的堆叠层数 | 12 |
| 头数 (num attention heads) | 多头自注意力的头数 | 12 |
| 前馈网络维度 (ffn hidden size) | 线性输出层的隐藏维度 | 3072 |
| 词汇表大小 (vocab size) | 词表大小 | 50257 |
| 最大序列长度 (max position embeddings) | 长下文长度 | 1024 |
| Dropout 比例 (dropout rate) | 防止过拟合的随机失活比例 | 0.1 |
| 激活函数 (activation function) | 提供非线性能力 | GELU |
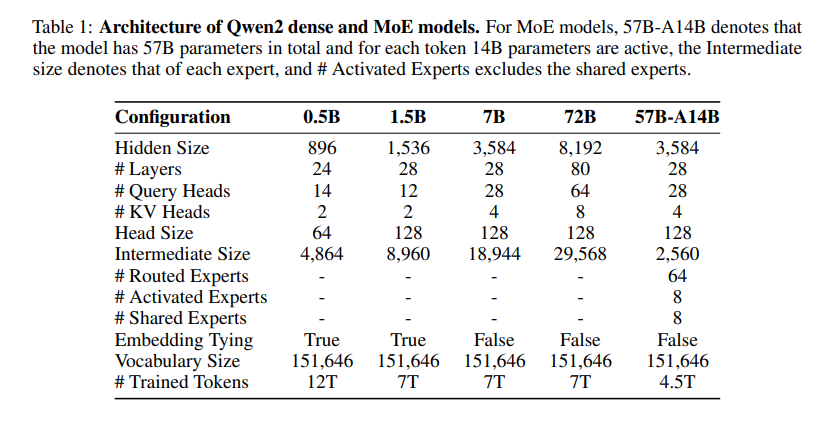
通过修改上述超参数,更改不同的训练数据便得到了不同的 LLM
下图展示了阿里巴巴训练的 Qwen2 开源大模型参数情况,截图自 Qwen2 的技术论文
多模态视角下的 Decoder-Only 架构
此处照例不对 NLP 算法做过多解释
多模态模型的主要目标是将来自不同模态的数据(如文本、图像、音频等)进行融合,以便模型能够理解并生成符合多种输入模态信息的输出
Decoder-Only 架构在这个过程中主要负责从融合后的输入中生成最终的输出
换言之,Decoder-Only 架构其实不具备多模态的处理能力,它只具备生成能力
现有的多模态 LLM 会针对每个模态的数据额外训练一个编码器,下面以 Qwen2-VL 的技术实现为例,不同多模态 LLM 的编码器实现可能有所差别
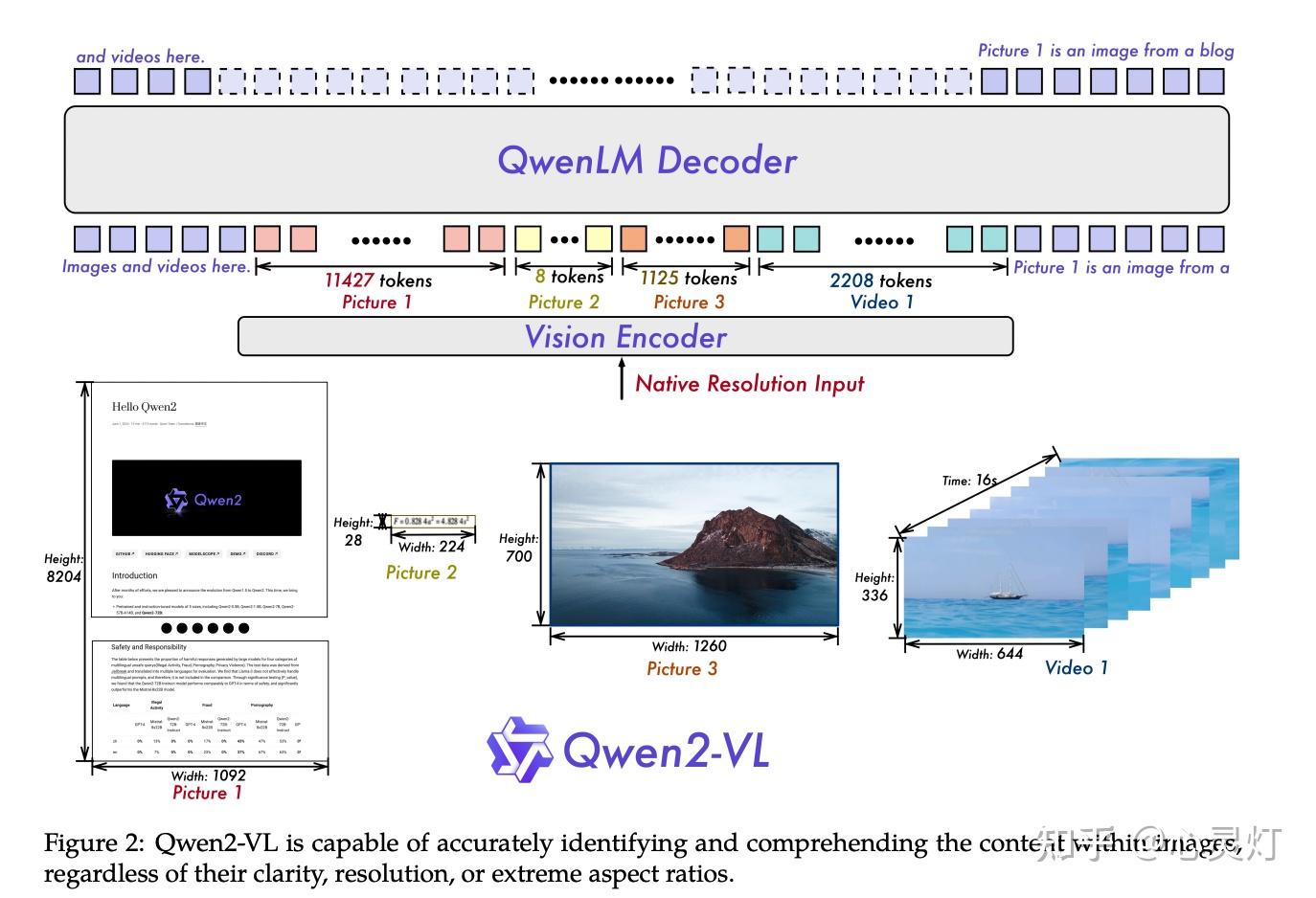
Qwen2-VL 可以针对动态分辨率的图片进行编码,并将视觉编码融入文本生成中
Qwen2-VL 的视觉编码器可以简单概括为下面四个步骤:
- 将图片按照 14 * 14 的大小进行分块,使用 ViT 对每个块进行编码,每个块得到一个 token
- 使用 MLP 将相邻的 2 * 2 大小的四个块进行合并,得到新的 token
- 针对视频数据,基于 3D-ViT 使用类似的编码,将图片和视频统一编码成一系列 token
- 将得到的一系列 token 前后补上 <img_start> 和 <img_end> 的特殊 token,将这一系列的 token 与输入文本结合,剩余流程与 Decoder-Only 架构重合
Qwen2-VL 采用混合训练方案,结合图像和视频数据,确保在图像理解和视频理解方面的熟练度。为了尽可能完整地保留视频信息,以每秒两帧的频率采样每个视频
对于一张 224 * 224 大小的图片,Qwen2-VL 会使用 ViT 将其编码为 224/14 * 224/14 = 16 * 16 = 256 个 token,再使用 MLP 进行 2 * 2 大小的 token 合并,得到 256 / 4 = 64 个 token,前后补上 <img_start> 和 <img_end> 的特殊 token,再将最后得到 64 + 2 = 66 个 token 直接当作用户的文本输入,进行文本生成
换言之,对于 Qwen2-VL 而言,一张 224 * 224 的图片等效于 66 个 token,也就是用户额外输入了 66 个词语
对于其他的多模态数据,比如音频、文本等,也可以采用相似的编码逻辑,将输入编码成一系列的 token,并在前后补上类似 <audio_start> 和 <audio_end> 的特殊 token 即可
Decoder-Only 架构统一带来的好处
下面内容复制自 ChatGPT/乐
- 一致性:统一架构减少了不同团队实现之间的差异性
- 可复用性:开发者可以复用已优化的组件
- 更好的比较:行业中不同模型的能力可以在相似的条件下进行直接对比
- 优化空间明确:让超参数调优和架构改进有了明确的目标,比如针对上下文长度进行优化
- 硬件兼容性:使针对 Decoder-Only 架构的硬件加速更加有效
- 资源共享:不同模型可以共享相同的训练和推理软件工具链
商业化使用
你可以商业化地使用开源的 LLM,可以通过各种 API 访问这些模型
OpenAI 提供了一个强大和统一的 LLM 交互 API,这些 API 允许用户执行各种任务,如文本生成、情感分析、翻译、代码生成、文本摘要等
除了 OpenAI 提供的 API,大部分的云厂商或者本地的 LLM 服务器也都采用了 OpenAI 的 API 风格
接下来介绍一下 OpenAI 的 API 规范,一些不成文的规定
请求 URL
OpenAI 提供的 API 通常遵循 RESTful 风格,使用 HTTP 请求来访问和交互。常见的请求方法包括 POST 和 GET
POST 用于创建对话和生成模型响应,GET 用于检索特定的信息,如模型列表或已处理的对话
- Base URL:
https://api.openai.com/v1/ - 接口示例:
https://api.openai.com/v1/completions用于生成文本https://api.openai.com/v1/chat/completions用于对话https://api.openai.com/v1/models用于列出可用模型
而对于非 Openai 的厂商,它们的 API URL 也会采用类似的设置
以云厂商 Deepseek 为例,其 Base URL 为 https://api.deepseek.com/
其相关的接口依次为:
https://api.deepseek.com/completions用于生成文本https://api.deepseek.com/chat/completions用于对话https://api.deepseek.com/models用于列出可用模型
本地 LLM 服务器也不例外,以 Ollama 为例
Ollama 一般运行在本地,对应的 Base URL 为 localhost:11434/v1/
其相关的接口依次为:
https://localhost:11434/v1/completions用于生成文本https://localhost:11434/v1/chat/completions用于对话https://localhost:11434/v1/models用于列出可用模型
身份验证
为了保护 API 免受滥用,OpenAI API 使用 API 密钥进行身份验证
开发者需要在请求头部附加一个有效的 API 密钥
对应的请求头:
1 | Authorization: Bearer <API_KEY> |
而对于非 OpenAI 的厂商,也是在相同的地方设置对应的密钥 Key
API 请求格式
与 LLM 交互的请求格式也是统一的,参考下方的 python 代码
1 | import requests |
下面是这个请求的参数解释
url:- 这是对应 API 云厂商的请求 URL
headers:Authorization:用于身份验证的 API 密钥Content-Type:指定请求体的格式为 JSON
data:model:指定要使用的模型message:输入的上下文信息temperature:控制生成内容的随机性。值在0和1之间,此值越高回复随机性越强max_tokens:指定模型生成文本的最大 token 数量top_p:指定输出的多样性。取值范围为 0 到 1,此值越高表示词语选择越随机frequency_penalty:控制模型对重复文本的惩罚。此值越大,生成的文本重复性越低presence_penalty:控制模型在生成文本时引入新话题的程度。范围为-2.0到2.0,较高的值会促使模型讨论新的话题stop:这是一个列表,定义生成文本的停止标记
这些参数要求对于任何符合 OpenAI API 规范的请求平台都是一致的
下面着重解释一下 message 参数
请求参数 Message
在 OpenAI API 中,message 参数是用于与模型进行对话的关键部分。它允许你在一个对话中指定多轮交互,通常包括不同的角色(role)和内容(content)。这个参数主要用于聊天类型的接口,比如 gpt-3.5-turbo 或 gpt-4 等模型,也适用于指令微调或者 prompt 工程。
message 参数是一个列表,每个元素都是一个字典,包含两个关键字段:
role:发送消息的角色,指定消息的来源或发送者,共有三种角色:system:用于设置模型的行为、角色或背景信息,通常不参与对话,但影响后续生成的内容user:表示用户的输入assistant:表示模型的回应
content:消息的实际内容,通常是文本字符串。内容可以是问题、命令或生成的文本,取决于消息的角色
下面给出一个综合使用了三种角色的 message 示例,主要用于上下文对话
1 | [ |
而在一般的 prompt 工程中,可以这么设置 message,只要用于设置 LLM 的偏好
1 | [ |
在指令微调中,可以这么设置 message,让 LLM 依据特定的行为完成一项任务
1 | [ |
响应格式
API 的响应通常是 JSON 格式,包含生成的文本、token 计数、模型的状态等信息
以下是一个使用 GPT-4o 的 API 响应示例,这是一个多模态 LLM:
1 | { |
一般我们通过 response["choices"][0]["message"][content] 来获取 LLM 的回复文本
可参考的交互模板
下面给出一般 Python 调用云服务 LLM 的模板代码
1 | from openai import OpenAI |
本地使用
HuggingFace 模型文件规范
Hugging Face 的模型仓库文件规范是指用于在 Hugging Face Hub 上传、分享和管理模型的文件结构和规范
通过这些规范,开发者和研究人员可以方便地将机器学习模型共享给社区,也可以将预训练模型加载和使用
- config.json:模型的配置文件,包括架构,层数,隐藏单元数,注意力头数等超参数
- generation_config.json:模型生成任务相关的配置,如生成文本时的温度、最大长度等参数
- model-xxxxx-of-xxxxx.safetensors:分片模型权重文件,用于存储大规模模型的实际权重
- model.safetensors.index.json:索引文件,指示如何组合和加载模型权重文件
- special_tokens_map.json:此文件定义了特殊标记(如
<PAD>、<BOS>、<EOS>等)的映射关系 - tokenizer.json:该文件包含词汇表和编码/解码规则
- tokenizer_config.json:tokenizer 配置相关的参数,如分词器类型、预处理步骤等
下方是 Llama3.1-8B 的文件结构
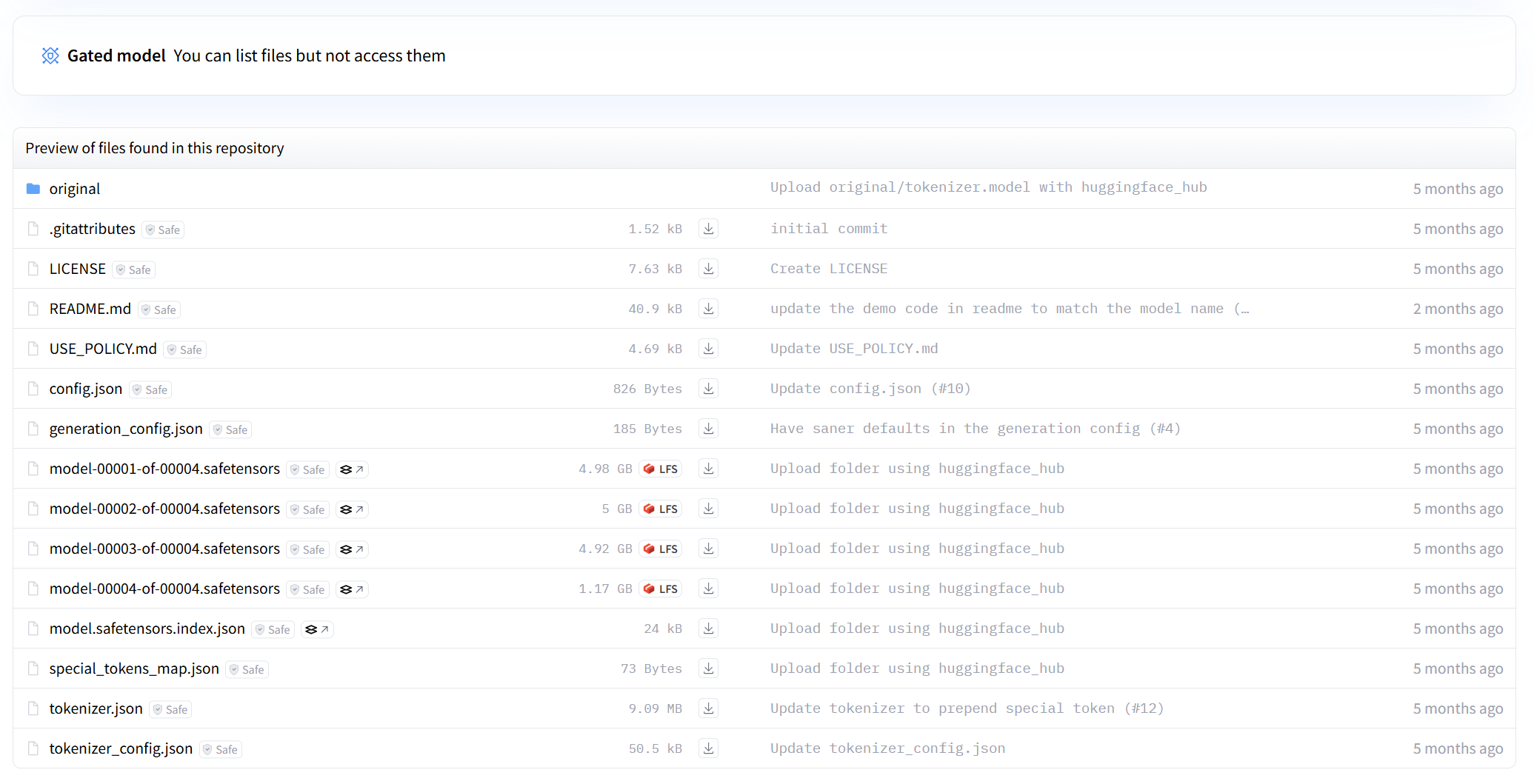
Hugging Face 的这些文件规范统一了开源 LLM 的下载、加载、使用方式
部署本地 LLM 服务器
这里给出两个不错的本地 LLM 服务器软件
依照官方的文档指引,这两个本地 LLM 服务器部署成功后,便可以使用上文提到的 OpenAI API 进行 LLM 的交互
其中 Ollama 的 Base URL 为 localhost:11434/,vLLM 的 Base URL 为 localhost:8000/v1/
这两个软件都自带了多卡推理、模型量化、推理加速的功能,对于仅需要推理的实验而言,非常够用
用于本地训练
有时我们需要针对开源 LLM 进行训练或者额外组件的训练,比如数据集微调或者做 CoT、RLHF 的研究
下面给出针对符合 Hugging Face 模型文件规范的开源 LLM 权重加载方式
下面的场景都刻意回避了框架的实现,下面的实现只是一个原理的演示
单卡部署
transformers 依赖底层深度学习框架(比如 Pytorch)运行,transformers 是一个工具库,可以便捷下载、加载符合 Hugging Face 规范的 LLM
可以选择直接用 transformers 加载,此时 transformers 库会自动去 http://www.huggingface.co 下载对应的权重模型,并加载到一张显卡上
1 | from transformers import AutoTokenizer, AutoModelForCausalLM |
想要自行指定下载的位置,可以采用如下方案
1 | import transformers |
数据并行
数据并行是一种常见的跨显卡训练和推理的方式,它通过将数据分割成多个批次,并将它们分配给不同的显卡进行处理
DataParallel 是 PyTorch 的一个简单接口,能够让模型自动复制到多个 GPU 上
1 | import torch |
DataParallel 不会对模型进行切分,每个显卡上都有一份完整的模型
它只将数据分割成多个批次,分配给不同的显卡进行处理
模型并行
对于非常大的模型,单个 GPU 无法容纳所有参数时,需要采用模型并行技术
模型并行将模型的不同部分放在不同的 GPU 上,从而在多张显卡之间分配模型的计算和存储
Hugging Face 提供了 accelerate 库,它更方便地支持跨多张显卡的训练和推理,尤其是在分布式环境下
1 | from accelerate import Accelerator |
Accelerator 库会自动检测可用的 GPU,并将模型和数据分配到各个 GPU 上
张量并行
张量并行是一种更细粒度的并行化方式,通过在不同的 GPU 上分配计算图中的每个操作来将模型分割为更小的部分
DeepSpeed 库支持张量并行,以优化大规模模型的加载和推理
1 | import deepspeed |
模型量化
量化是将模型权重和激活值从高精度降低到较低精度的过程
这可以大大减少模型的存储需求,提高推理速度,尤其是在硬件加速器上
- 权重量化
权重量化是指将模型的权重从浮点数转换为低位整数
PyTorch 提供了量化 API,如 torch.quantization,支持静态量化和动态量化
1 | import torch |
- 激活量化
激活量化是将神经网络中的激活值从浮点数转换为低精度整数
激活量化通常需要在训练过程中进行,以便进行优化
1 | from transformers import AutoTokenizer, AutoModelForCausalLM |
- 混合精度训练
混合精度训练是指在训练过程中使用不同的数值精度
这通常涉及使用 半精度浮动点数 来训练模
PyTorch 提供了 torch.cuda.amp 来简化混合精度训练
1 | from torch.cuda.amp import autocast, GradScaler |
Reference
- https://openai.com/index/gpt-2-1-5b-release/
- https://github.com/openai/gpt-2
- https://arxiv.org/pdf/2407.10671
- https://qwenlm.github.io/zh/blog/qwen2-vl/
- https://github.com/QwenLM/Qwen2-VL
- https://github.com/google-research/vision_transformer
- https://openai.com/api/
- https://api-docs.deepseek.com/zh-cn/api/deepseek-api/
- https://www.llamafactory.cn/ollama-docs/api.html
- https://docs.vllm.ai/en/stable/getting_started/quickstart.html
- https://huggingface.co/meta-llama/Llama-3.1-8B
- https://github.com/huggingface/transformers
 wechat
wechat